 知源-AI数据分类分级系统
知源-AI数据分类分级系统 知形-数据库风险监测系统
知形-数据库风险监测系统 知影-API风险监测系统
知影-API风险监测系统 知镜-数据安全检测工具
知镜-数据安全检测工具 一站式-数据安全管理平台
一站式-数据安全管理平台 数据出境-合规治理平台
数据出境-合规治理平台 数据安全咨询-服务
数据安全咨询-服务 数据安全评估-服务
数据安全评估-服务 数据安全测评-服务
数据安全测评-服务 数据安全认证-服务
数据安全认证-服务 轻量合规服务-DiRM
轻量合规服务-DiRM 数据安全治理综合方案
数据安全治理综合方案 数据安全分类分级方案
数据安全分类分级方案 内部人员数据风险管理方案
内部人员数据风险管理方案 黑灰产及护网API安全方案
黑灰产及护网API安全方案 数据安全风险评估解决方案
数据安全风险评估解决方案 数据安全咨询服务规划方案
数据安全咨询服务规划方案 政务数据共享安全解决方案
政务数据共享安全解决方案 保险业数据安全解决方案
保险业数据安全解决方案 运营商数据安全解决方案
运营商数据安全解决方案 互联网数据安全解决方案
互联网数据安全解决方案 教育行业数据安全解决方案
教育行业数据安全解决方案news
全知动态


合规法定前提
数字经济时代,数据已从“资产”跃升为核心生产要素,贯穿企业业务全链路、流转于API、数据库、FTP、VPN、SSH等全通道。数据流动创造价值的同时,泄露风险、合规压力、治理困境也随之而来——从用户隐私泄露到核心商业机密失窃,从监管高额罚款到业务停滞,数据安全已成为企业不可逾越的生命线。
而数据治理的第一道、也是最关键的一道门槛,便是数据分类分级。它不仅是《数据安全法》《个人信息保护法》及国标 GB/T 43697-2024《数据安全技术 数据分类分级规则》明确要求的法定合规义务,更是企业摸清数据家底、界定敏感边界、落实全生命周期防护、释放数据价值的核心根基。没有精准的分类分级,后续所有数据安全防护、风险监测、审计溯源、合规建设,都将沦为 “无源之水、无本之木”。
但当下,90%以上企业仍深陷传统分类分级的落地困局,投入巨大却收效甚微,合规治理举步维艰:
高成本、低精度、难适配、无联动,传统分级模式已走到尽头
1.人力投入无底洞,效率与成本严重失衡
传统分类分级依赖 “业务 + IT + 安全” 多部门协同,纯人工梳理、规则制定、正则编写、逐条校验。金融、政务等中大型企业,面对10万级数据表、百万级字段,动辄投入数十人、耗时3-6个月,且需持续专人维护。业务快速迭代、数据结构变更,便需推倒重来,长期人力成本居高不下,与企业轻量化、高效化治理需求背道而驰。
2.识别精度两极分化,脏数据场景近乎“失明”
传统方案过度依赖字段注释、命名规范与人工正则,仅能精准识别手机号、身份证号等少数通用个人信息。面对金融、政务、医疗、教育、运营商等行业专属敏感数据,识别能力薄弱;一旦遇到字段命名混乱、注释缺失、脏数据频发的真实场景,识别准确率骤降至30%-50%,大量核心敏感数据漏标、错标,分类分级结果形同虚设,安全防护无从谈起。
3.异构环境适配难,复杂数据生态覆盖不足
企业数据环境日趋复杂,关系型、非关系型、大数据平台、国产数据库并存,形成异构混合架构。传统分类分级工具仅支持少数主流关系型数据库,对MongoDB、Redis、Hive、达梦、人大金仓、高斯等数据库适配性差;新增数据库类型需定制开发,适配周期长达1-2个月,无法快速覆盖企业全量数据资产,治理盲区长期存在。
4.结果孤立无联动,全通道防护沦为空谈
多数企业完成分类分级后,结果仅停留在单一数据库层面,无法同步至API、FTP、VPN、SSH等数据流转全通道。各通道防护标准不一、数据孤岛林立,敏感数据跨通道流转时,无统一标签、无精准防护、无有效溯源。看似完成合规动作,实则数据安全 “漏洞百出”,一旦泄露,根本无法追溯源头、界定责任,合规落地与安全治理彻底脱节。

不同领域,共性困局下的差异化难题
金融行业:客户征信、交易数据、信贷信息高度敏感,人工梳理易泄露,漏标敏感字段将引发巨额赔付、监管处罚、牌照吊销风险;
政务行业:居民身份证、户籍、社保、不动产等民生数据,量大且杂、命名不规范,传统模式效率低下,泄露将导致监管追责、公信力受损、社会稳定风险;
医疗行业:患者病历、诊疗记录、基因数据隐私性极强,跨科室、跨系统流转频繁,无统一分类分级标准,易引发医患纠纷、隐私侵权、合规重罚;
教育行业:学籍、招生、考试、学生隐私数据密集,字段注释缺失普遍,传统正则识别准确率低,易被不法分子利用,引发电信诈骗、个人信息泄露;
运营商行业:用户通话记录、位置信息、消费数据体量庞大、更新频繁,人工维护跟不上业务迭代,敏感数据泄露将导致用户流失、品牌声誉崩塌、合规问责。
全知破局——AI原生驱动,打造全通道数据安全统一底座
深耕数据安全领域近十年,全知科技作为国内API安全先行者、全通道数据安全守护者,深刻洞察行业痛点与治理本质。依托在流量解析、AI大模型、数据治理领域的深厚积淀,全知科技AI数据分类分级系统应运而生——作为五层全通道数据安全监测体系的地基层核心产品,以AI原生技术彻底颠覆传统模式,打破效率、精度、适配、联动四大瓶颈,为全行业提供自动化、高精准、全适配、强联动的数据分类分级解决方案,筑牢数据安全第一道、也是最关键的一道根基。
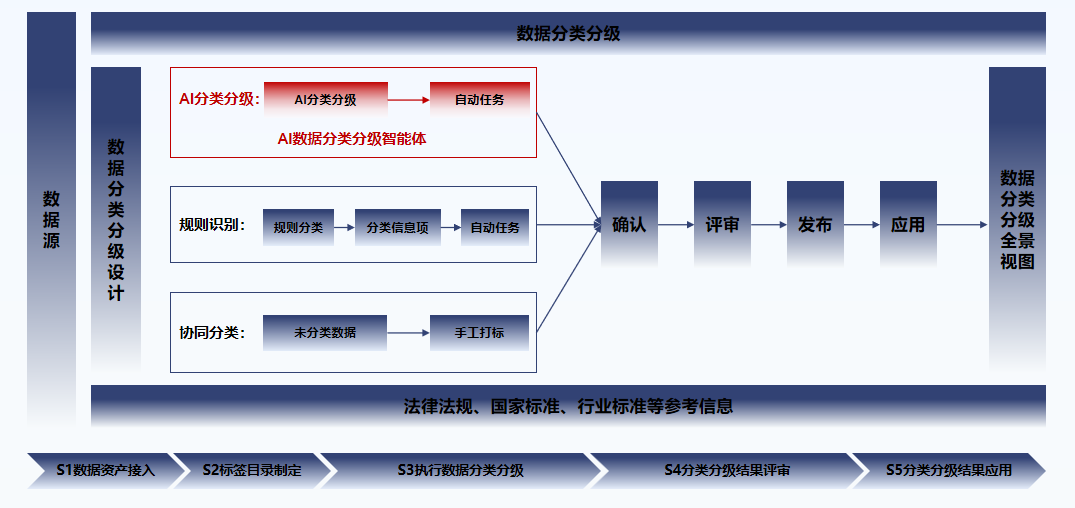
五大核心能力:直击痛点,从根源破解数据治理难题
1. 纯AI免正则识别,人力成本直降90%+
摒弃 “人工定规则、写正则、逐条校验” 的传统路径,内置全知沉淀多年的金融、政务、医疗、教育、运营商等行业分类分级专家经验,深度融合AI大模型语义理解能力。无需编写任何正则,即可自动识别字段语义、数据特征、业务关联,完成全量数据分类分级。
仅需少量人工校准即可落地,综合人力成本降低90%以上;
日均处理字段量达12万个,教育行业8000+字段仅需90分钟完成全量梳理;
彻底解放安全、业务、IT人力,让团队从重复低效的梳理工作中解脱,聚焦核心安全运营与业务创新。
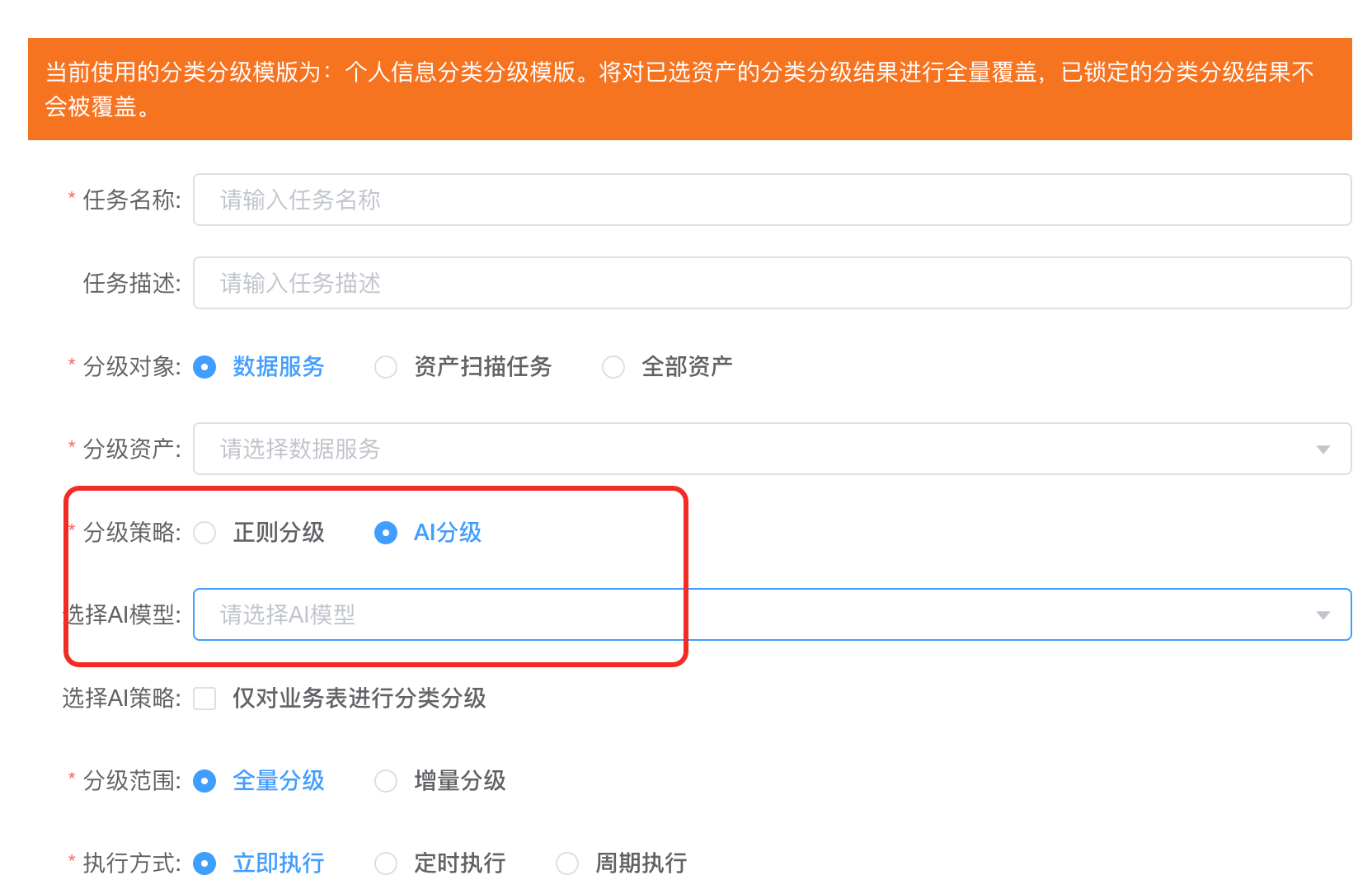
2. 双场景高精准打标,全资产无死角识别
突破传统 “注释依赖” 瓶颈,针对企业真实数据质量场景,构建双维度精准识别能力,敏感数据分布一目了然、无死角覆盖:
注释齐全场景:精准识别个人信息、行业专属敏感数据,识别准确率达95%以上;
注释缺失/命名混乱场景:AI自动补全数据字典、深度理解语义关联,优化后准确率仍达70%以上;
自动完成全域数据资产盘点,生成标准化数据台账,清晰呈现敏感数据分布、资产类型、风险等级、流转路径,让企业真正摸清数据家底。
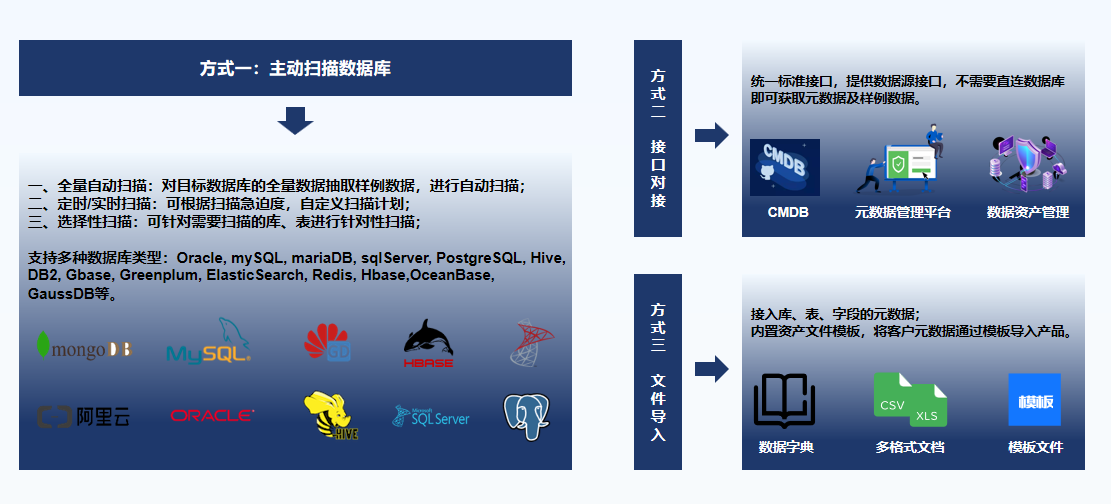
3. 全类型数据库兼容,5分钟快速适配
全面覆盖企业30+全类型数据存储形态,无兼容死角、无适配门槛,适配能力远超行业同类产品:
关系型数据库:MySQL、Oracle、SQL Server、PostgreSQL、DB2 等;
非关系型数据库:MongoDB、Redis、Elasticsearch、HBase 等;
大数据平台:Hive、Spark、ClickHouse、OceanBase、Greenplum 等;
国产数据库:达梦、人大金仓、高斯、南大通用、优炫等。
针对默认不支持的数据库类型,无需定制开发,仅需从官网下载驱动、在产品页面上传,5分钟即可完成适配;全程旁路无扰部署,不改造业务系统、不占用核心算力、不中断业务运行,小型企业3天、大型集团一周即可完成全量资产梳理,快速落地使用。
4. 全通道标准同步,统一全链路依据
严格遵循国标GB/T 43697-2024及各行业专项规范,输出统一、标准化的分类分级模板,实现 “一次打标、全链复用”:
分类分级结果无缝同步至API、数据库、FTP、VPN、SSH等所有数据流转通道;
让后续风险监测、实时防护、审计溯源、合规审计均基于同一套数据标准;
从根源解决 “各通道标准不一、防护无据、合规脱节、溯源无门” 的行业顽疾,构建全链路统一数据安全治理体系。
5. AI自动学习迭代,业务变化零维护
AI模型具备自主学习、动态优化、持续进化能力,彻底告别传统模式 “业务一变、规则重做、反复维护” 的致命短板:
跟随业务迭代、数据结构变更、新增数据类型,自动优化分类策略、更新识别模型;
沉淀行业项目经验至RAG知识库,模型越用越准、识别越做越强;
一次部署,长期可用,长期维护成本趋近于零,适配企业业务快速迭代节奏,实现数据治理的可持续发展。
想了解更多产品适配方案与功能细节,扫描文末二维码,即可申领新产品免费试用。
四大核心价值:赋能企业数字化发展
合规价值:原生适配监管要求,直接满足审计需求
内置等保2.0、数据安全法、个人信息保护法及各行业专项合规逻辑,输出的分类分级报告、数据资产台账、敏感数据分布报表,可直接用于监管审计、合规自查、等保测评,省去额外整改、补材料成本,一站式满足合规要求,规避百万级罚款与问责风险。
安全价值:精准识别敏感数据,从源头阻断泄露风险
通过高精准分类分级,清晰界定敏感数据边界、分布与流转路径,为后续数据库漏洞防护、API风险监测、跨通道访问控制提供精准依据,从源头识别敏感数据泄露风险、阻断异常访问、防止批量外泄,构建“精准识别、精准防护、精准溯源”的数据安全闭环。
业务价值:摸清数据资产家底,释放数据价值
全面盘点企业数据资产,清晰呈现数据类型、敏感等级、流转路径、业务归属,打破数据孤岛,支撑企业数据共享、合规流通、价值挖掘、业务创新,让数据资产从 “沉睡资源” 转化为 “价值引擎”,助力企业数字化转型与业务增长。
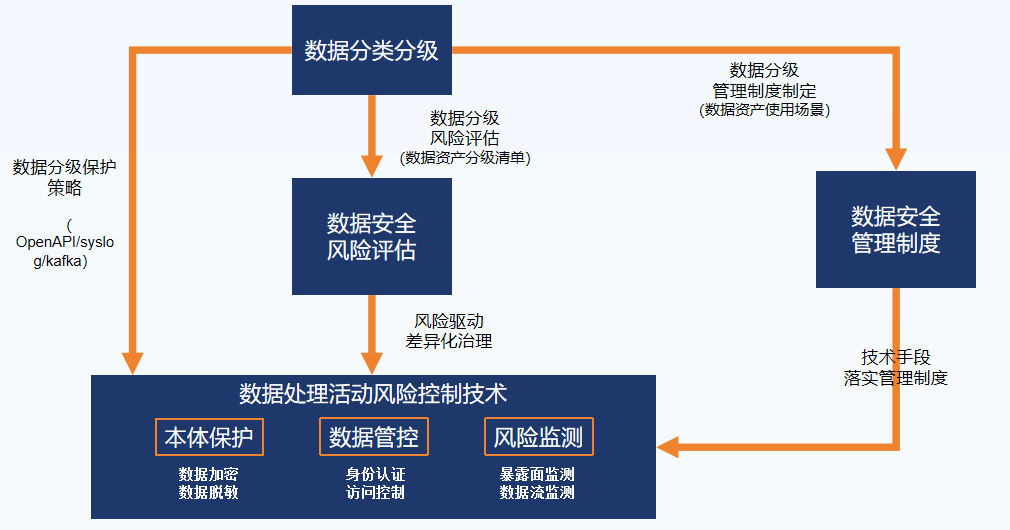
体系价值:筑牢全通道安全底座,联动全产品闭环
作为全知科技五层全通道数据安全监测体系(地基层→解析层→监测层→防护层→管控层) 的核心底座,AI数据分类分级系统的输出结果可无缝对接数据库风险监测系统、数据安全监测平台、知影-API风险监测系统等全系列产品。形成“数据摸底(AI 分类分级)→风险监测(数据库/API)→统一管控(监测平台)→实时防护(流量网关)→审计溯源(全链路日志)”的完整安全闭环,不是孤立的工具,而是企业全链路数据安全治理的核心基石,助力企业实现从API安全先行者到全通道数据安全守护者的战略升级。
数据安全,始于知数;知数之基,在于分级。在数字经济纵深推进、数据安全合规趋严的时代大势下,数据分类分级早已不是单一的合规动作,而是企业筑牢数据安全防线、释放数据价值的核心根基。唯有先把数据家底摸清、把敏感等级定准、把标准体系建牢,后续的流动监测、风险防护、审计溯源才能有据可依、有章可循。
全知科技坚守“数据在流动,可见才安全”理念,将数年数据安全深耕积淀融入AI数据分类分级系统,以AI技术破除传统模式桎梏,以体系化思维夯实全通道数据安全底座,让企业从“数据无序、底数不清”的困境中破局而出,真正实现数据资产可感知、可治理、可防护。
未来,全知将持续以技术创新为引擎,以合规落地为导向,以稳固的数据安全底座,护航企业数字化行稳致远,共筑可信、可控、可溯的数据安全新生态。

.png)




